




人声分离+深度学习+开源资源包=你的老婆
1.概述
主要用到的就是so-vits-svc,一个深度学习歌声转换的工具。我们需要提供的一段音频,交给深度学习模型进行训练,再用训练出的模型拟合另外一段音频,这样就实现了用a的声线唱b的歌曲,需要注意的是两段音频都必须是纯人声,这也是为什么我们会用到人声分离。
2.原料
人声分离uvrs下载
Release v5.6 - UVR GUI · Anjok07/ultimatevocalremovergui (github.com)
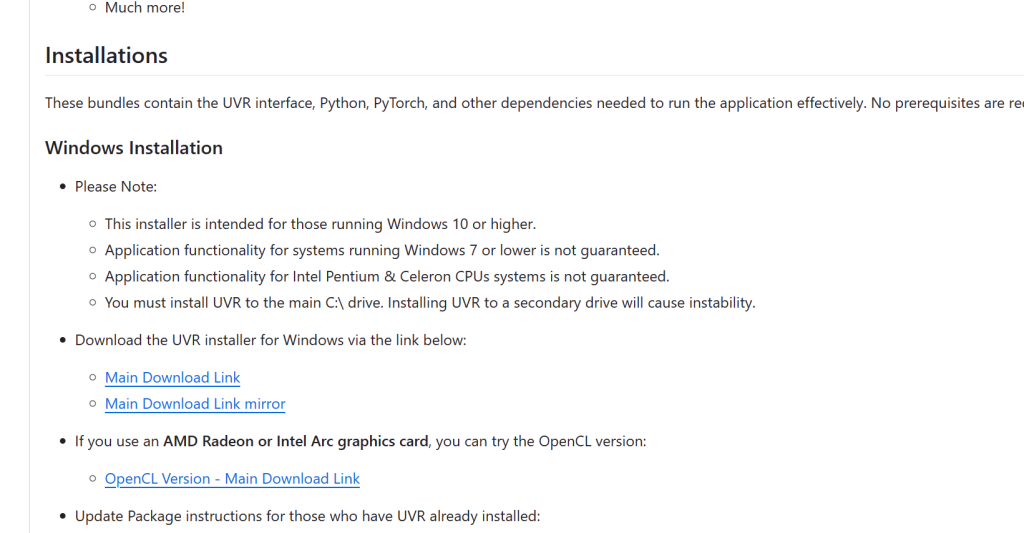
我们的电脑是windows系统,于是选择main_download_link。
so-vits资源包下载
如果你有梯子
https://drive.google.com/file/d/19e7HJYk32WHVIXm-CuhvbwF8IHjZ48QU/view?usp=sharing
如果你没有
https://pan.baidu.com/s/12u_LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4
3.操作流程
打开资源包,找到启动webui并打开它(你的默认浏览器最好是google)

准备一段音频作为训练音频,在打开的网页的小工具一栏找到切片
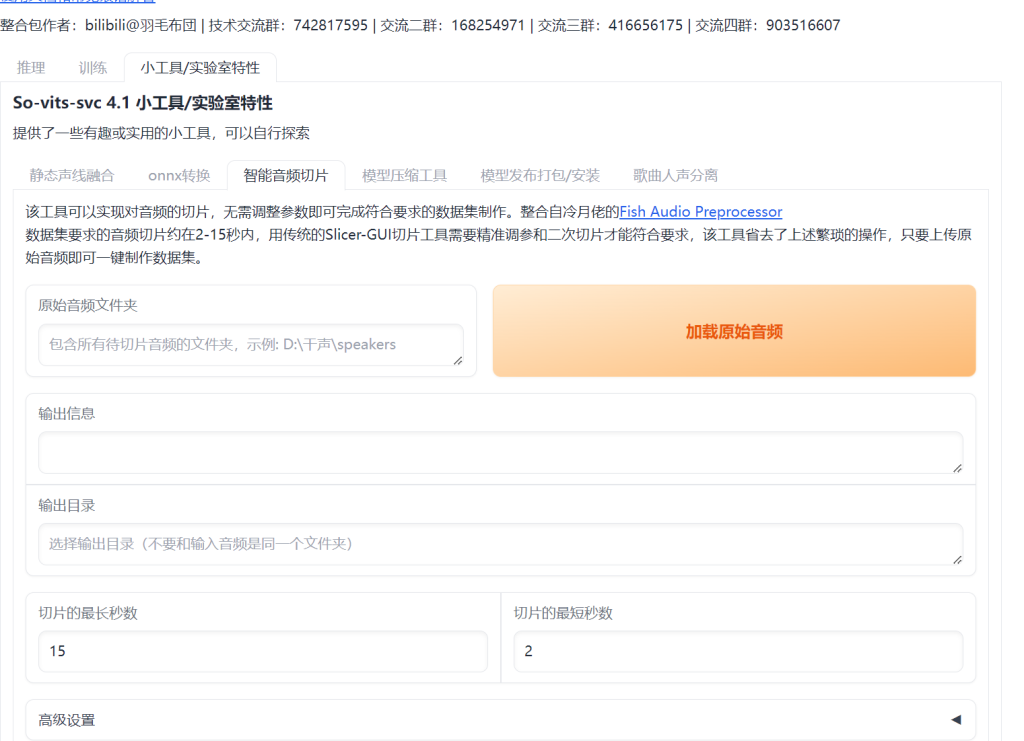
将你准备的音频文件夹写上去,点击加载,开始切片,注意如果你的音频比较短的话,可以尝试设置最短秒数小一点。
切片后将切片文件夹放到data_raw文件夹之中,这就是我们的训练集。
接着开始训练,在网页中找到训练栏目,点击识别数据集,选项什么的不用动,接着点下面的数据预处理
至于聚类模型什么的我也没搞明白,暂时先不管,不影响的。
等待数据预处理进度条达到100%(可能会比较久,如果你在处理过程中突然未响应或者黑屏,立刻关闭浏览器!可以尝试提高你的虚拟内存(方法在这里不展开,可以自己搜))
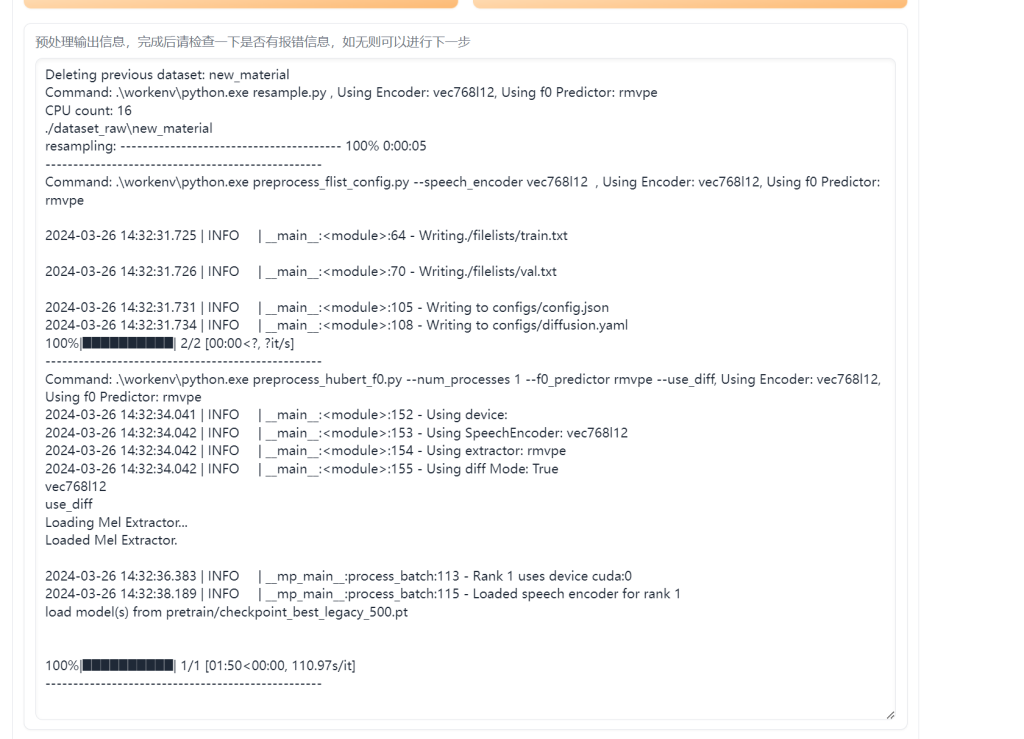
预处理完成后点击下方生成配置文件,就可以开始训练啦。
如果你是第一次训练就选从头开始,否则就选继续。
另外,我们可以自定义保存步数,默认800步,也就是说,假如我们训练了1599步就停止了,那么我们只能得到G_800这一个模型。
当你训练了3000步以上时,就可以开始推理了。
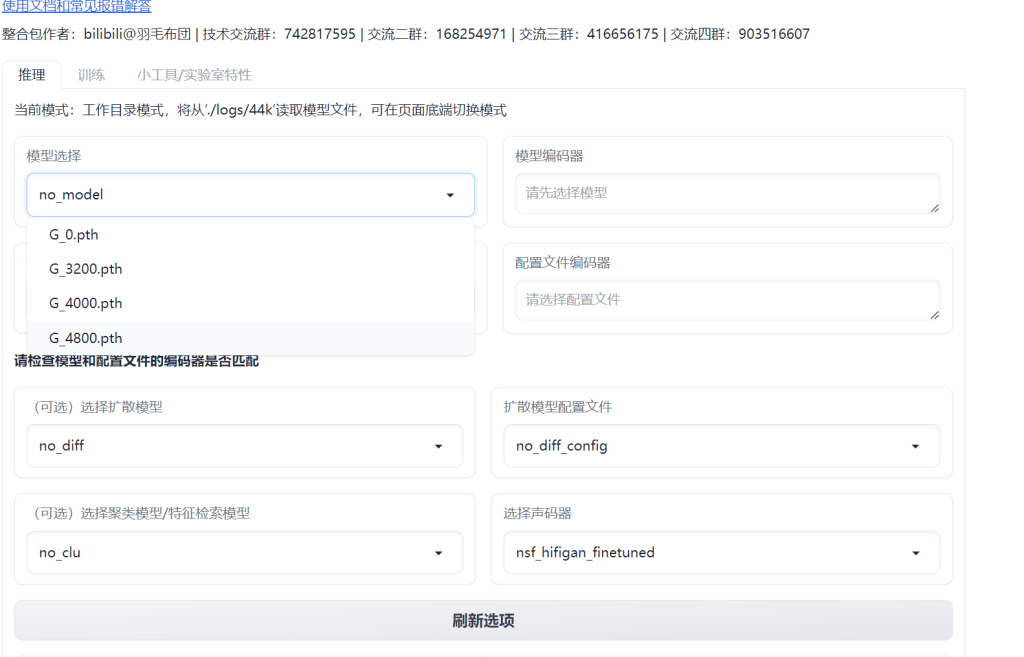
选择你的模型和配置文件,点击加载模型,成功后就可以在下方上传一段纯人声,并用你训练好的声线复述了,下面的三个选项对应着上面的三个功能。
至于如何从一首歌中获得纯人声,就需要用到uvr了,使用方法非常简单,不需要说明都能看懂。
Comments | NOTHING